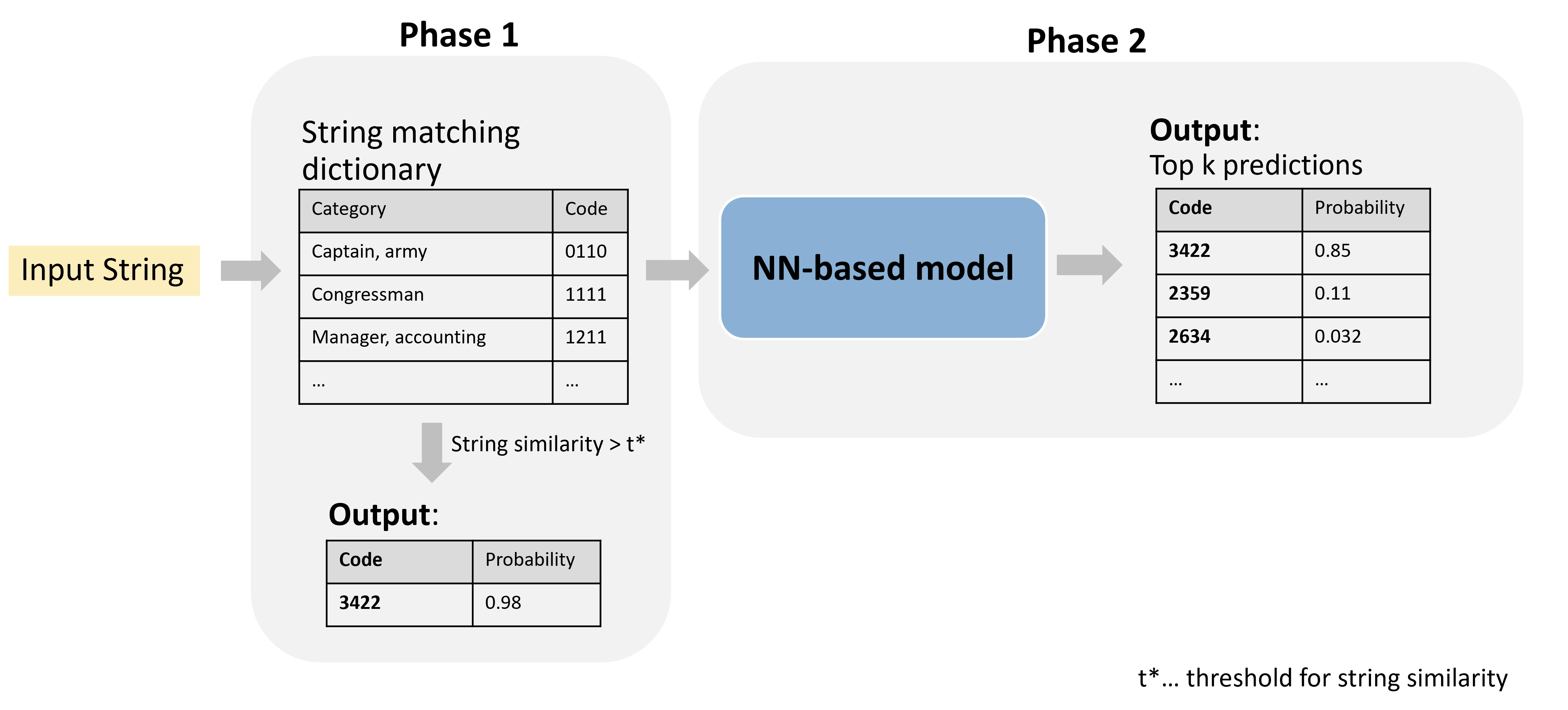
Model Approach
Our model-based approach is divided into two main phases: Phase 1, string matching, and Phase 2, the neural network (NN)-based model. This approach is visualized in Figure 1.
Pre-processing
As a first step in this pipeline, we perform pre-processing on the input strings. This includes transforming all characters to lowercase, removing stop words (e.g., “and,” “to,” “for”) and special characters (e.g., “-,” “%,” “&”), and converting any umlaut characters to non-umlauts (e.g., “ü” to “u”). Additionally, we remove gender-specific word endings, such as “-in” in German, to maintain consistency.
String Similarity (Phase 1)
For the pre-processed strings, we compute the similarity of each string to entries in a predefined dictionary using the string distance measure. This results in one similarity score per dictionary entry, where we find the maximum similarity. If this maximum value exceeds a certain threshold, the input string is assigned the corresponding code automatically. This process allows us to filter out a significant portion of strings that do not require further processing.
Transformer Models (Phase 2)
For input strings that could not be automatically classified using string matching, the pre-processed text is split into n-grams. We typically use 3-grams and 5-grams for our models. Each n-gram (or token) is assigned a unique token ID, which transforms each word into a token ID vector. We construct token ID vectors of fixed-length by padding shorter vectors with trailing zeros. Additionally, we apply one-hot encoding to all token IDs and any additional available variables. We then transform the ones in the one-hot encoded token ID matrix to their respective TF-IDF values.
Our final models have multiple input streams: the first and second n-gram inputs, each followed by embeddings, positional encodings, and a transformer encoder; and the one-hot encoded inputs, followed by a dense layer, dropout, and ReLU activation layer. These three inputs are then merged into a single output layer, producing one probability per class. The final model architecture can be seen in Figure 2.
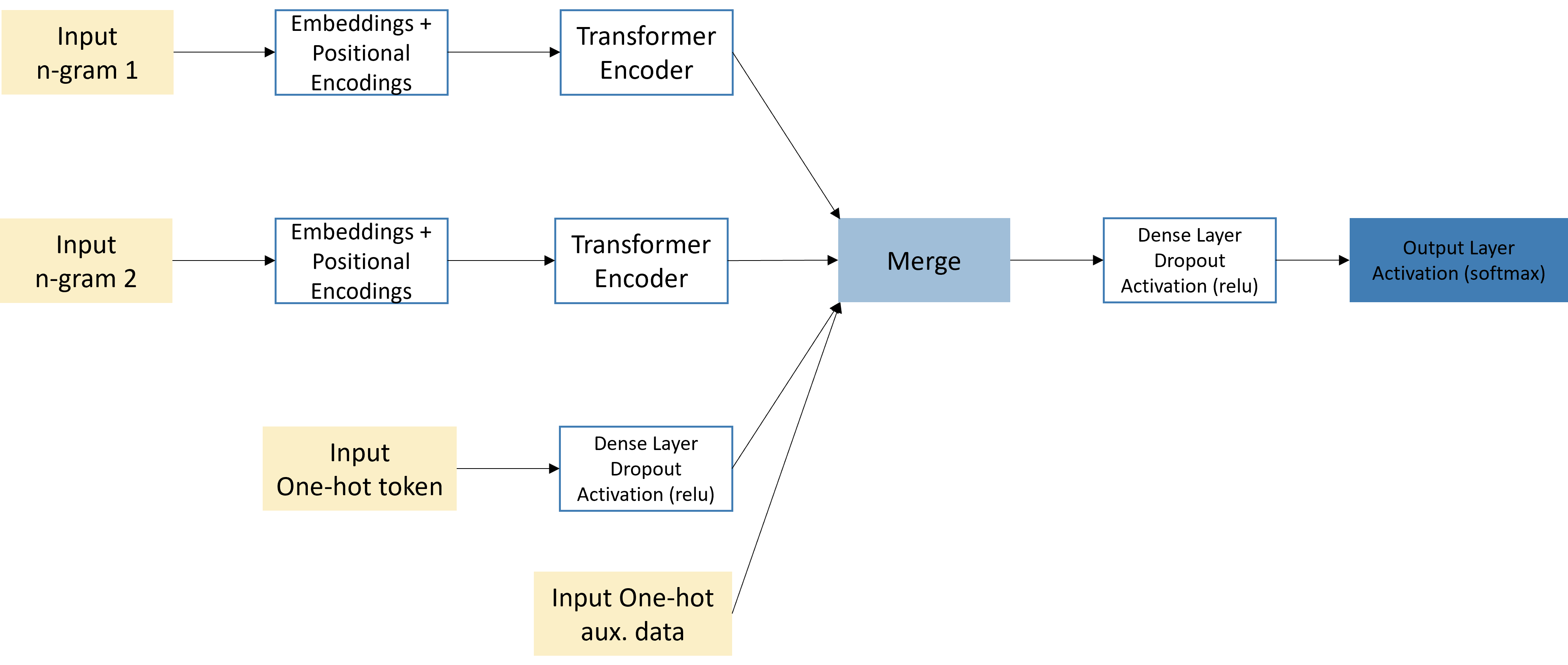
We fine-tune the transformers’ hyper parameters to improve model accuracy. The average model has around 10 million parameters. Increasing the model size further tends to reduce performance, likely due to over-fitting on the relatively small training data.
By default, our model outputs the top 5 predictions per input string. If the model can classify a string with very high certainty, only the top prediction is included in the output. These cases are fully automatized and do not undergo further manual inspection. We set this threshold for high-certainty classification at 0.98.